|
Cong Wei I am a 3rd year PhD student in Computer Science at University of Waterloo, advised by Wenhu Chen. Previously, I earned my master’s degree in Computer Science from the University of Toronto, where I was advised by Florian Shkurti. I also completed my undergraduate studies at the University of Toronto. During my undergraduate years, I was a student researcher at the Vector Institute, advised by David Duvenaud and Gennady Pekhimenko. Email / Google Scholar / Twitter / Github / Linkedin |

|
News
10/2025:
MoCha is accepted to NeurIPS 2025 (Spotlight)
03/2025: Thrilled to introduce
MoCha! Enjoy the Promotional Video!
02/2025:
OmniEdit is accepted to ICLR 2025.
10/2024: I will join Meta GenAI as a Research Scientist Intern in 2024 Winter.
|
ResearchI'm broadly interested in multimodal generation and multimodal understanding. I build scalable data synthesis methods for data creation and design unified architectures that generalize across tasks. |
Publications[show selected / show all by date](*: Indicating equal contribution.) |
|
|
UniVideo: Unified Understanding, Generation, and Editing for Videos
Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, Wenhu Chen ICLR 2026 website / hf page / paper / code Unifed models for image/video understanding and generation |
|||||

|
Context Forcing: Consistent Autoregressive Video Generation with Long Context
Shuo Chen*, Cong Wei*, Sun Sun, Ping Nie, Kai Zhou, Ge Zhang, Ming-Hsuan Yang, Wenhu Chen arXiv 2026 website / paper / code Real-time 60s+ long video generation with long context |
|||||
|
|
MoCha: Towards Movie-Grade Talking Character Synthesis
Cong Wei, Bo Sun, Haoyu Ma, Ji Hou, Felix Juefei-Xu, Zecheng He, Xiaoliang Dai, Luxin Zhang, Kunpeng Li, Tingbo Hou, Animesh Sinha, Peter Vajda, Wenhu Chen NeurIPS 2025 (Spotlight Presentation) website / hf page / paper / tweet Automated Filmmaking |
|||||
|
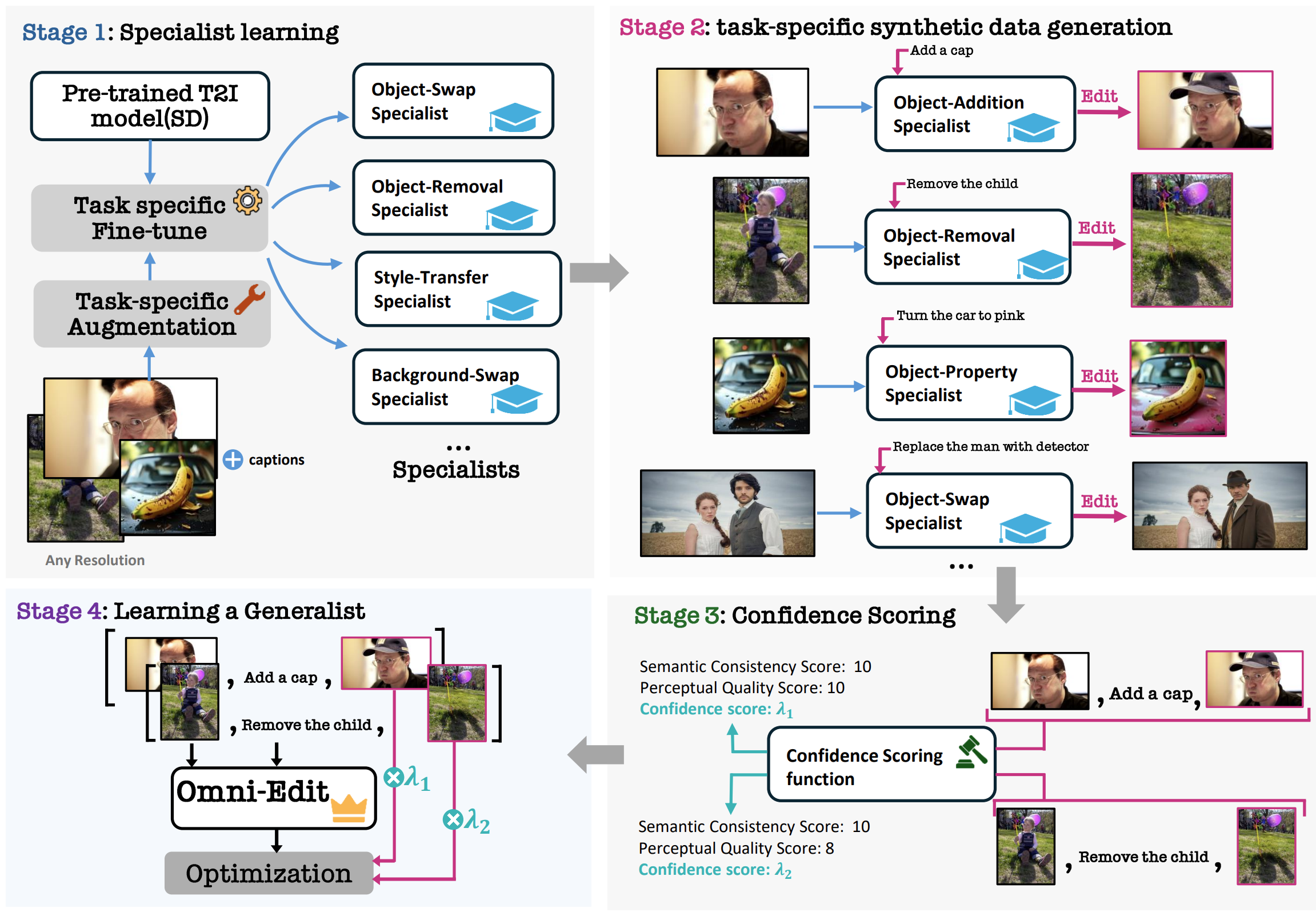
OmniEdit: Building Image Editing Generalist Models Through Specialist Supervision
Cong Wei*, Zheyang Xiong*, Weiming Ren, Xinrun Du, Ge Zhang, Wenhu Chen ICLR 2025 paper / dataset / website / tweet A method to scale up image editing training data: Multi-Experts generation + LLM filtering |
|||||
|
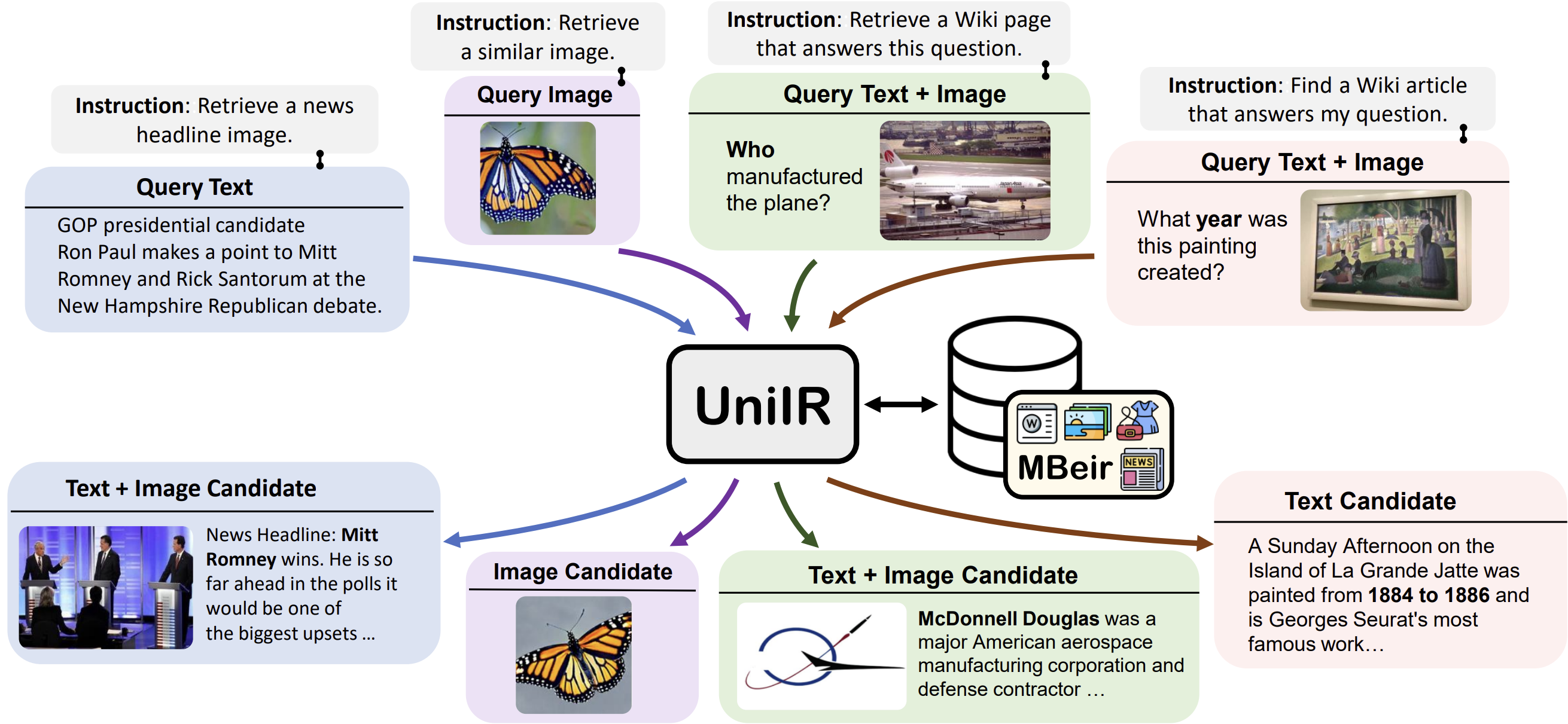
UniIR: Training and Benchmarking Universal Multimodal Information Retrievers
Cong Wei, Yang Chen, Haonan Chen, and Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, Wenhu Chen ECCV 2024 (Oral Presentation) paper / website / tweet A unified multimodal instruction guided retriever |
|||||
|
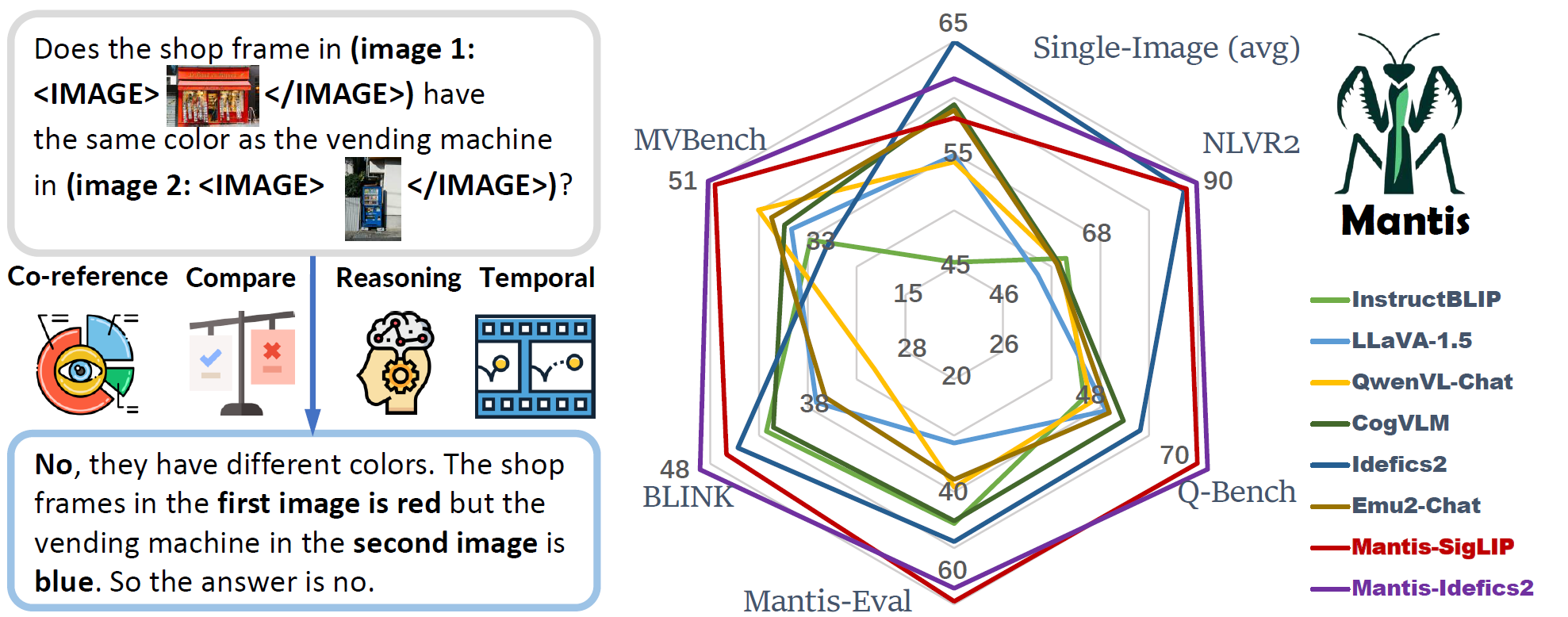
MANTIS: Interleaved Multi-Image Instruction Tuning
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, Wenhu Chen TMLR 2024 (TMLR 2024 Outstanding/Best Paper Award) paper / website / code Multi-image Understanding |
|||||

|
Sparsifiner: Learning Sparse Instance-Dependent Attention for Efficient Vision Transformers
Cong Wei*, Brendan Duke*, Ruowei Jiang, and Parham Aarabi, Graham W Taylor, Florian Shkurti CVPR 2023 paper / website / video Learning to Sparsify Attention Pattern in ViT |
|||||
|
|
AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks
Max Ku*, Cong Wei*, Weiming Ren*, Harry Yang, Wenhu Chen TMLR 2024 (TMLR 2024 Reproducibility Certification) tweet / website / paper A training-free V2V method that can be used to generate video editing data. |
|||||
|
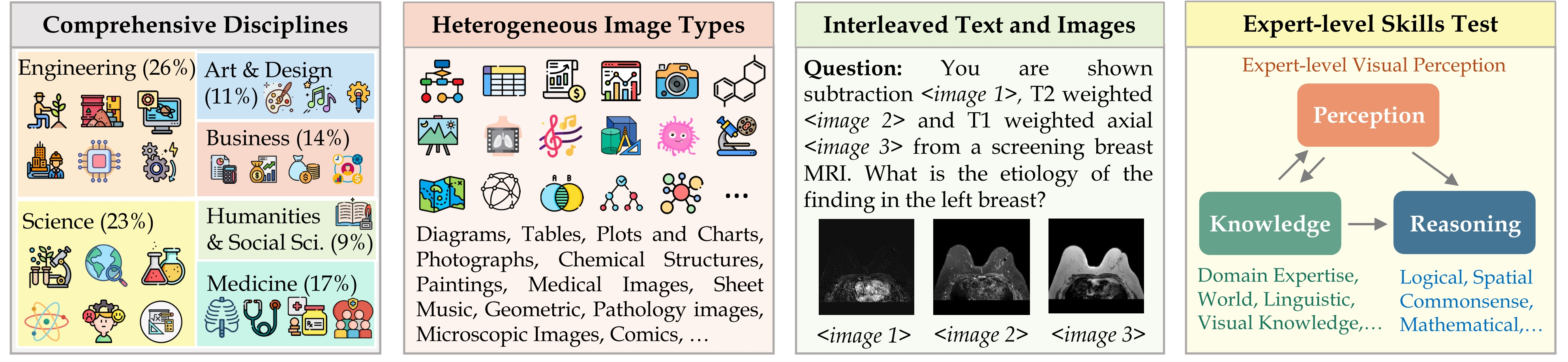
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, Wenhu Chen CVPR 2024 (Oral Presentation)(Best Paper Finalist) paper / website A large scale benchmark for multimodal llm evaluation |
Education |
||||||
|


Experience |
||||||
|

|
|
|
Website source from Jon Barron |